In this comprehensive tutorial, we’ll build a powerful RSS feed reader using Streamlit, a Python library that makes it easy to create interactive web applications with minimal effort. RSS (Really Simple Syndication) feeds allow users to keep up with frequently updated content from various websites without having to visit each site individually. Our RSS reader will provide a centralized dashboard to aggregate, manage, and display content from multiple feeds.
What We’ll Build
Our RSS feed reader will have these key features:
- Feed Management System: Add, view, and remove RSS feeds dynamically through a user-friendly sidebar
- Dual View Options: View feed entries in two formats – a visually appealing card view and a data-rich table view
- Auto-Refresh Capability: Keep content fresh with configurable refresh intervals
- Content Cleaning: Remove HTML tags and format content for improved readability
- Consistent Date Formatting: Handle various date formats from different feeds
- Error Handling: Gracefully handle feed parsing errors and missing data
- Responsive Design: Create a clean, modern interface that works on various screen sizes
Why Streamlit?
Streamlit is an excellent choice for this project because:
- Rapid Development: Build interactive web applications in pure Python without frontend experience
- Built-in Components: Leverage pre-built UI elements like sidebars, tabs, and data displays
- Session State: Maintain application state between reruns for a seamless user experience
- Automatic Reactivity: Components update automatically when their dependencies change
- Easy Deployment: Deploy applications with minimal configuration
Prerequisites
To follow along, you’ll need:
- Python 3.7 or higher is installed on your system
- Basic knowledge of Python programming
- Familiarity with web concepts like RSS feeds and HTML
- A text editor or IDE (like VS Code, PyCharm, etc.)
- Command-line knowledge for running installation commands
Step 1: Setting Up the Project Environment
First, let’s create a dedicated project directory and set up our environment:
# Create project directory mkdir rss-feed-reader cd rss-feed-reader # Create a virtual environment (recommended) python -m venv venv # Activate the virtual environment # On Windows: venv\Scripts\activate # On macOS/Linux: source venv/bin/activate # Install required packages pip install streamlit feedparser pandas beautifulsoup4 requests python-dateutil
Now, let’s create a requirements.txt file to document our dependencies and make it easier for others to install them:
# requirements.txt streamlit # For creating the web application feedparser # For parsing RSS feeds pandas # For data manipulation and table display beautifulsoup4 # For cleaning HTML content requests # For making HTTP requests python-dateutil # For date parsing and formatting
Each dependency serves a specific purpose:
- Streamlit: The core framework for building our web application
- Feedparser: A powerful RSS feed parser that handles most feed formats
- Pandas: For data manipulation and creating the table view
- BeautifulSoup4: For parsing and cleaning HTML content from feed entries
- Requests: For making HTTP requests, if we need to fetch additional content
- Python-dateutil: For parsing various date formats from different feed sources
Step 2: Building the Core Application Structure
Now, let’s create our main application file app.py and import the necessary libraries:
import streamlit as st import feedparser import pandas as pd from datetime import datetime import time from bs4 import BeautifulSoup import requests from dateutil import parser
Page Configuration and Styling
First, we’ll set up the page configuration and add custom CSS to style our feed items:
# Set page config - this affects the entire application
st.set_page_config(
page_title="RSS Feed Reader",
page_icon="📰",
layout="wide", # Utilize the full width of the browser
initial_sidebar_state="expanded" # Start with sidebar expanded
)
# Custom CSS for styling feed items
# This is injected directly into the HTML of the page
st.markdown("""
<style>
.feed-item {
padding: 15px;
border-radius: 5px;
margin-bottom: 15px;
background-color: #f0f2f6;
box-shadow: 0 1px 2px rgba(0,0,0,0.1);
transition: all 0.3s ease;
}
.feed-item:hover {
transform: translateY(-2px);
box-shadow: 0 4px 6px rgba(0,0,0,0.1);
}
.feed-title {
font-weight: bold;
font-size: 18px;
color: #0f2b46;
margin-bottom: 5px;
}
.feed-date {
color: #606060;
font-size: 14px;
margin-bottom: 10px;
}
.feed-summary {
margin-top: 10px;
line-height: 1.5;
color: #333;
}
a.read-more {
display: inline-block;
margin-top: 10px;
color: #4d8bdd;
text-decoration: none;
font-weight: 500;
}
a.read-more:hover {
text-decoration: underline;
}
.divider {
margin: 30px 0;
border-bottom: 1px solid #e0e0e0;
}
</style>
""", unsafe_allow_html=True)
# App title with emoji for visual appeal
st.title("📰 RSS Feed Reader")
st.markdown("*Stay updated with all your favorite content in one place*")Our CSS adds several important visual enhancements:
- Card-like appearance for each feed item
- Hover effects for better interactivity
- Consistent typography with appropriate spacing
- A color scheme that’s easy on the eyes
- Visual separation between sections
Step 3: Implementing Feed Management
Next, we’ll create a sidebar for feed management with features to add, display, and remove feeds:
# Sidebar for feed management
with st.sidebar:
st.header("Feed Management")
# Default feeds to get users started
default_feeds = [
"https://news.google.com/rss",
"https://feeds.bbci.co.uk/news/rss.xml",
"https://rss.nytimes.com/services/xml/rss/nyt/HomePage.xml"
]
# Initialize session state for feeds if it doesn't exist
# This persists feeds between reruns of the app
if 'feeds' not in st.session_state:
st.session_state.feeds = default_feeds
# Add new feed section
st.subheader("Add New Feed")
new_feed = st.text_input("Enter RSS feed URL",
placeholder="https://example.com/feed.xml")
# Validate and add the new feed
if st.button("Add Feed", use_container_width=True) and new_feed:
# Simple URL validation
if not new_feed.startswith(('http://', 'https://')):
st.error("Please enter a valid URL starting with http:// or https://")
elif new_feed not in st.session_state.feeds:
# Add feed and show success message
st.session_state.feeds.append(new_feed)
st.success(f"Added: {new_feed}")
else:
st.warning("Feed already exists in your list!")
# Display and manage existing feeds
st.subheader("Your Feeds")
if not st.session_state.feeds:
st.info("No feeds added yet. Add some feeds to get started!")
# List all feeds with remove buttons
for i, feed in enumerate(st.session_state.feeds):
col1, col2 = st.columns([3, 1])
with col1:
# Display feed URL, truncating if too long
display_url = feed if len(feed) < 30 else feed[:27] + "..."
st.text(f"{i+1}. {display_url}")
# Show full URL on hover using HTML
if len(feed) >= 30:
st.markdown(f"<small title='{feed}'>Hover for full URL</small>",
unsafe_allow_html=True)
with col2:
# Remove button for each feed
if st.button("Remove", key=f"remove_{i}", use_container_width=True):
st.session_state.feeds.pop(i)
st.rerun() # Rerun the app to update the UI
# Refresh settings
st.subheader("Settings")
# Auto-refresh interval selection
refresh_interval = st.slider(
"Auto-refresh interval (minutes)",
min_value=5,
max_value=60,
value=15,
step=5,
help="Select how often the feeds should automatically refresh"
)
# Manual refresh button
if st.button("Refresh Now", use_container_width=True):
st.rerun()
# About section
st.sidebar.markdown("---")
st.sidebar.subheader("About")
st.sidebar.info(
"This RSS Feed Reader is built with Streamlit. "
"It allows you to aggregate and read content from "
"various websites through their RSS feeds."
)This sidebar implementation includes several important features:
- Session State: We use Streamlit’s
session_stateto persist the list of feeds between app reruns - Input Validation: We perform basic validation to ensure the URLs start with http:// or https://
- Feed Management: Each feed can be individually removed
- URL Truncation: Long URLs are truncated with a hover feature to see the full URL
- Settings: Users can customize the auto-refresh interval
- Feedback Messages: Success, warning, and error messages provide user feedback
Step 4: Creating Utility Functions for Feed Processing
Now let’s add the functions to parse RSS feeds, clean HTML content, and format dates consistently:
# Function to parse RSS feed with error handling
def parse_feed(feed_url):
"""
Fetches and parses an RSS feed from the given URL.
Args:
feed_url (str): The URL of the RSS feed to parse
Returns:
tuple: (feed_data, error_message)
- feed_data: The parsed feed data or None if there was an error
- error_message: An error message if there was an error, or None if successful
"""
try:
# Set a timeout to avoid hanging on slow feeds
feed = feedparser.parse(feed_url, timeout=10)
# Check if the feed was parsed successfully
if feed.get('bozo_exception'):
return None, f"Failed to parse feed: {str(feed.bozo_exception)}"
# Check if the feed has entries
if not feed.entries and (not hasattr(feed, 'feed') or not feed.feed):
return None, "Feed contains no entries or is not a valid RSS feed"
return feed, None
except Exception as e:
return None, f"Error fetching feed: {str(e)}"
# Function to clean HTML content for better display
def clean_html(html_content):
"""
Cleans HTML content by removing tags and normalizing whitespace.
Args:
html_content (str): HTML content to clean
Returns:
str: Plain text content with normalized whitespace
"""
if not html_content:
return ""
try:
# Parse HTML content
soup = BeautifulSoup(html_content, 'html.parser')
# Get text content
text = soup.get_text()
# Normalize whitespace
text = ' '.join(text.split())
return text
except Exception:
# If parsing fails, return the original content
return html_content
# Function to format date consistently
def format_date(date_str):
"""
Parses and formats a date string to a consistent format.
Args:
date_str (str): Date string in any format
Returns:
str: Formatted date string in 'YYYY-MM-DD HH:MM' format
or the original string if parsing fails
"""
if not date_str:
return "Unknown date"
try:
# Parse the date string using dateutil.parser
# This is robust to many different date formats
dt = parser.parse(date_str)
# Format the date consistently
return dt.strftime("%Y-%m-%d %H:%M")
except Exception:
# If parsing fails, return the original string
return date_str
# Function to get a safe value from a dictionary
def safe_get(dictionary, key, default=""):
"""
Safely gets a value from a dictionary, returning a default if the key doesn't exist.
Args:
dictionary (dict): The dictionary to get the value from
key (str): The key to look up
default (any): The default value to return if the key doesn't exist
Returns:
any: The value for the key or the default
"""
return dictionary.get(key, default)These utility functions provide important capabilities:
- Robust Feed Parsing: The
parse_feedfunction includes error handling and timeout settings - HTML Cleaning: The
clean_htmlfunction removes HTML tags and normalizes whitespace - Date Standardization: The
format_datefunction ensures consistent date formatting - Safe Dictionary Access: The
safe_getfunction provides a way to safely access dictionary values
Step 5: Building the Main Content Area with Tabs
Our application will have two tabs for different views of the feed data:
# Create tabs for different views
tab1, tab2 = st.tabs(["📄 Feed View", "📊 Table View"])
# Collect all entries for use in both tabs
all_entries = []
# Function to fetch all feed content
def fetch_all_feeds():
"""
Fetches and processes all feeds, collecting entries for display.
Returns:
list: List of all processed feed entries
"""
entries = []
# Display a progress bar during feed fetching
with st.progress(0.0, text="Fetching feeds...") as progress_bar:
for i, feed_url in enumerate(st.session_state.feeds):
# Update progress
progress = (i / len(st.session_state.feeds))
progress_bar.progress(progress, text=f"Fetching {feed_url}...")
# Fetch and process feed
feed_entries = process_feed(feed_url)
entries.extend(feed_entries)
# Complete progress
progress_bar.progress(1.0, text="All feeds loaded!")
return entries
# Function to process a single feed
def process_feed(feed_url):
"""
Processes a single feed URL, extracting and formatting entries.
Args:
feed_url (str): The URL of the feed to process
Returns:
list: List of processed entries from this feed
"""
feed_entries = []
# Parse the feed
feed_data, error = parse_feed(feed_url)
if error:
st.error(f"Error parsing feed {feed_url}: {error}")
return feed_entries
if not feed_data or not feed_data.entries:
st.warning(f"No entries found in feed: {feed_url}")
return feed_entries
# Get feed title if available
feed_title = feed_url
if hasattr(feed_data, 'feed') and hasattr(feed_data.feed, 'title'):
feed_title = feed_data.feed.title
# Process each entry
for entry in feed_data.entries[:10]: # Limit to 10 entries per feed
# Extract data with fallbacks
title = safe_get(entry, 'title', 'No title')
link = safe_get(entry, 'link', '#')
# Get published date with fallbacks
published = None
for date_field in ['published', 'pubDate', 'updated', 'created']:
if date_field in entry:
published = entry[date_field]
break
if published is None:
published = 'Unknown date'
# Format the date
formatted_date = format_date(published)
# Try to get summary or description
summary = ""
for content_field in ['summary', 'description', 'content']:
if content_field in entry:
content = entry[content_field]
# Handle both string and dictionary/list formats
if isinstance(content, str):
summary = clean_html(content)
break
elif isinstance(content, list) and content:
# Some feeds use a list of content items
summary = clean_html(content[0].get('value', ''))
break
elif isinstance(content, dict):
# Some feeds use a dictionary with a 'value' key
summary = clean_html(content.get('value', ''))
break
# Create entry dictionary
entry_dict = {
'Feed': feed_title,
'Feed URL': feed_url,
'Title': title,
'Date': formatted_date,
'Link': link,
'Summary': summary[:500] + ('...' if len(summary) > 500 else '')
}
# Add to entries list
feed_entries.append(entry_dict)
return feed_entries
# Fetch all feed entries
all_entries = fetch_all_feeds()This implementation offers several advantages:
- Progress Feedback: Users see a progress bar during feed fetching
- Structured Processing: The code separates functionality into reusable functions
- Robust Content Extraction: We handle various feed formats and field names
- Detailed Error Handling: Each feed is processed independently with specific error messages
- Content Limiting: We prevent overwhelming the UI by limiting entries per feed
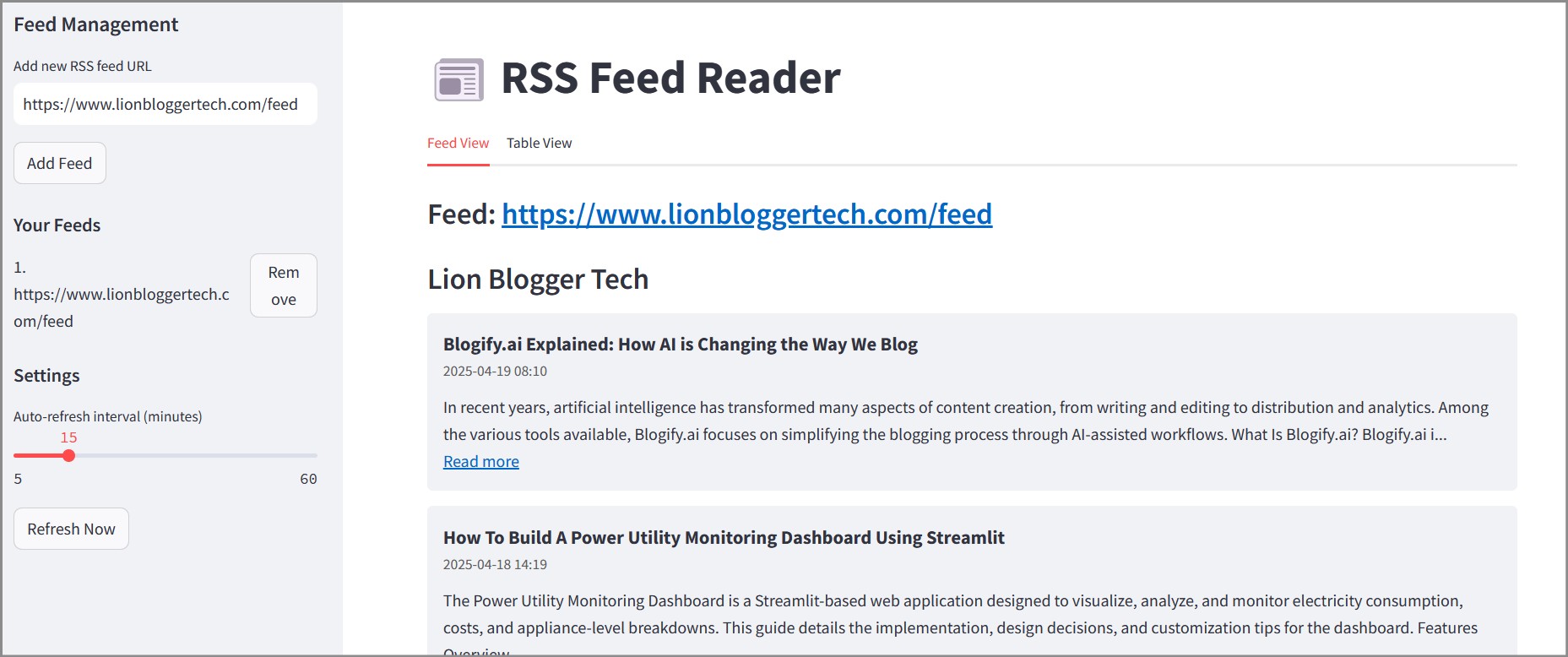
Step 6: Implementing the Feed View Tab
The Feed View tab displays entries in a card-like format:
# Feed View Tab
with tab1:
if not all_entries:
st.info("No feed entries to display. Add feeds from the sidebar or check for errors.")
else:
# Group entries by feed
from itertools import groupby
# Sort entries by feed name for grouping
sorted_entries = sorted(all_entries, key=lambda x: x['Feed'])
# Group entries by feed
for feed_name, feed_entries in groupby(sorted_entries, key=lambda x: x['Feed']):
# Convert to list since groupby returns an iterator
feed_entries = list(feed_entries)
# Display feed header with count
st.header(f"{feed_name} ({len(feed_entries)} articles)")
# Display each entry in this feed
for entry in feed_entries:
# Create a card-like display for each entry
st.markdown(f"""
<div class="feed-item">
<div class="feed-title">{entry['Title']}</div>
<div class="feed-date">{entry['Date']}</div>
<div class="feed-summary">{entry['Summary']}</div>
<a href="{entry['Link']}" target="_blank" class="read-more">Read more →</a>
</div>
""", unsafe_allow_html=True)
# Add divider between feeds
st.markdown('<div class="divider"></div>', unsafe_allow_html=True)The Feed View tab offers:
- Grouping by Source: Entries are organized by feed source
- Visual Hierarchy: Each feed has a header with the count of articles
- Card Interface: Each entry is displayed in a card with title, date, summary, and link
- Visual Separation: Dividers separate different feeds for clarity
Step 7: Implementing the Table View Tab
The Table View displays all entries in a sortable, filterable table:
# Table View Tab
with tab2:
if not all_entries:
st.info("No feed entries to display. Add feeds from the sidebar or check for errors.")
else:
# Create DataFrame from all entries
df = pd.DataFrame(all_entries)
# Add filters
st.subheader("Filters")
col1, col2 = st.columns(2)
with col1:
# Filter by feed source
feed_sources = ['All'] + sorted(df['Feed'].unique().tolist())
selected_feed = st.selectbox("Filter by feed source:", feed_sources)
with col2:
# Date range filter
date_options = ['All', 'Today', 'This week', 'This month']
date_filter = st.selectbox("Filter by date:", date_options)
# Apply filters
filtered_df = df.copy()
if selected_feed != 'All':
filtered_df = filtered_df[filtered_df['Feed'] == selected_feed]
if date_filter != 'All':
# Convert date strings to datetime objects for filtering
try:
# Extract date part only
filtered_df['DateObj'] = pd.to_datetime(filtered_df['Date'].str.split(' ').str[0])
today = pd.Timestamp.now().normalize()
if date_filter == 'Today':
filtered_df = filtered_df[filtered_df['DateObj'] == today]
elif date_filter == 'This week':
start_of_week = today - pd.Timedelta(days=today.dayofweek)
filtered_df = filtered_df[filtered_df['DateObj'] >= start_of_week]
elif date_filter == 'This month':
start_of_month = today.replace(day=1)
filtered_df = filtered_df[filtered_df['DateObj'] >= start_of_month]
# Drop the temporary column
filtered_df = filtered_df.drop('DateObj', axis=1)
except Exception as e:
st.warning(f"Could not filter by date: {str(e)}")
# Display table with filtered data
st.subheader(f"Showing {len(filtered_df)} entries")
# Reorder and select columns for display
display_columns = ['Feed', 'Title', 'Date', 'Summary', 'Link']
if 'Feed URL' in filtered_df.columns:
display_columns.insert(1, 'Feed URL')
# Display the table with custom formatting
st.dataframe(
filtered_df[display_columns],
column_config={
"Link": st.column_config.LinkColumn("Article Link"),
"Summary": st.column_config.TextColumn(
"Summary",
width="large",
help="Article summary with HTML removed"
),
"Date": st.column_config.TextColumn("Published Date", width="medium"),
"Feed": st.column_config.TextColumn("Source", width="medium"),
},
use_container_width=True,
hide_index=True
)
# Export functionality
if st.button("Export as CSV"):
# Convert to CSV
csv = filtered_df.to_csv(index=False).encode('utf-8')
# Provide download button
st.download_button(
"Download CSV",
csv,
"rss_feed_data.csv",
"text/csv",
key='download-csv'
)The Table View offers advanced functionality:
- Filtering Options: Users can filter by feed source and date range
- Column Configuration: Custom column widths and formats for better readability
- Export Feature: Users can download the data as a CSV file
- Count Display: Shows the number of entries after filtering
- Link Column: Clickable links to the original articles
Step 8: Implementing Auto-refresh Functionality
To keep the feeds up-to-date, we’ll add an auto-refresh feature:
# Auto-refresh logic
if refresh_interval:
# Convert minutes to seconds
refresh_sec = refresh_interval * 60
# Create a container for refresh information
refresh_container = st.container()
with refresh_container:
st.markdown("---")
st.subheader("Auto-refresh Status")
# Initialize last refresh time in session state if not present
if 'last_refresh' not in st.session_state:
st.session_state.last_refresh = time.time()
# Calculate time since last refresh
elapsed = time.time() - st.session_state.last_refresh
remaining = max(0, refresh_sec - elapsed)
# Display progress bar for refresh countdown
progress_percent = 1 - (remaining / refresh_sec)
st.progress(min(1.0, progress_percent))
# Create two columns for status display
col1, col2 = st.columns(2)
with col1:
# Show last refresh time
last_refresh_time = datetime.fromtimestamp(st.session_state.last_refresh)
st.text(f"Last refreshed: {last_refresh_time.strftime('%Y-%m-%d %H:%M:%S')}")
with col2:
# Show countdown
mins, secs = divmod(int(remaining), 60)
st.text(f"Next refresh in: {mins}m {secs}s")
# Check if it's time to refresh
if elapsed >= refresh_sec:
st.session_state.last_refresh = time.time()
st.rerun()
# Footer with app info
st.markdown("---")
st.markdown("""
<div style="text-align: center; color: #888;">
<p>📰 RSS Feed Reader App • Created with Streamlit</p>
<p><small>Refresh interval: {refresh_interval} minutes •
Feed count: {feed_count}</small></p>
</div>
""".format(
refresh_interval=refresh_interval,
feed_count=len(st.session_state.feeds)
), unsafe_allow_html=True)The auto-refresh implementation includes:
- Visual Countdown: A progress bar shows time until the next refresh
- Time Display: Both last refresh time and time until next refresh are shown
- Automatic Triggering: The page reruns automatically when the interval elapses
- Responsive Footer: Displays the current settings and feed count
Running the Application
To run the application, use the following command from your project directory:
streamlit run app.py
The application will open in your default web browser at http://localhost:8501, and you’ll immediately see:
- Pre-configured Feeds: Default news feeds already loaded
- Feed Management Sidebar: Interface to add/remove feeds
- Two View Options: Feed View and Table View tabs
- Auto-Refresh Status: Shows when the next refresh will occur
Advanced Customization Options
Here are some ways you could extend the application:
1. Feed Categories
# Add category field to feeds
if 'feed_categories' not in st.session_state:
st.session_state.feed_categories = {}
# Allow setting a category when adding a feed
category = st.selectbox("Category", ["News", "Technology", "Finance", "Sports", "Other"])
if st.button("Add Feed") and new_feed:
# Store the feed and its category
st.session_state.feeds.append(new_feed)
st.session_state.feed_categories[new_feed] = category2. Favorite Articles
# Allow marking articles as favorites
if 'favorites' not in st.session_state:
st.session_state.favorites = []
# Add favorite button to each article
if st.button("⭐ Favorite", key=f"fav_{entry_index}"):
st.session_state.favorites.append(entry)3. Feed Search Functionality
# Add search functionality
search_term = st.text_input("Search articles:", placeholder="Enter keywords...")
if search_term:
# Filter entries containing the search term
filtered_entries = [e for e in all_entries if search_term.lower() in e['Title'].lower()
or search_term.lower() in e['Summary'].lower()]
display_entries = filtered_entries
else:
display_entries = all_entriesConclusion
In this comprehensive tutorial, we’ve built a fully functional RSS feed reader using Streamlit. The application demonstrates the power of Python for creating interactive web applications with minimal code.
Key takeaways from this project:
- Streamlit’s Simplicity: Creating interactive web applications without traditional web development
- Python’s Ecosystem: Leveraging libraries like feedparser, BeautifulSoup, and pandas for complex functionality
- User Experience Design: Building an intuitive interface with multiple views and interactive elements
- State Management: Using session state to maintain application state between reruns
- Error Handling: Implementing robust error handling for better reliability
This RSS reader provides a solid foundation to extend with additional features like feed categorization, article search, content filtering, or authentication for personal feed collections.
Happy coding!