Apache Druid is a real-time analytics database designed for fast slice-and-dice analytics on large data sets. Most often, Druid powers use cases where real-time ingestion, fast query performance, and high uptime are important.
Druid is commonly used as the database backend for GUIs of analytical applications, or for highly-concurrent APIs that need fast aggregations. Druid works best with event-oriented data.
Common application areas for Druid include:
- Clickstream analytics including web and mobile analytics
- Network telemetry analytics including network performance monitoring
- Server metrics storage
- Supply chain analytics including manufacturing metrics
- Application performance metrics
- Digital marketing/advertising analytics
- Business intelligence/OLAP
To get started, download the tar folder and extract it. Then run the microstart script.
apache-druid-0.22.0/bin$ ./start-micro-quickstart [Sun Nov 21 13:43:37 2021] Running command[zk], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/zk.log]: bin/run-zk conf [Sun Nov 21 13:43:37 2021] Running command[coordinator-overlord], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/coordinator-overlord.log]: bin/run-druid coordinator-overlord conf/druid/single-server/micro-quickstart [Sun Nov 21 13:43:37 2021] Running command[broker], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/broker.log]: bin/run-druid broker conf/druid/single-server/micro-quickstart [Sun Nov 21 13:43:37 2021] Running command[router], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/router.log]: bin/run-druid router conf/druid/single-server/micro-quickstart [Sun Nov 21 13:43:37 2021] Running command[historical], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/historical.log]: bin/run-druid historical conf/druid/single-server/micro-quickstart [Sun Nov 21 13:43:37 2021] Running command[middleManager], logging to[/apps/Druid/apache-druid-0.22.0/var/sv/middleManager.log]: bin/run-druid middleManager conf/druid/single-server/micro-quickstart
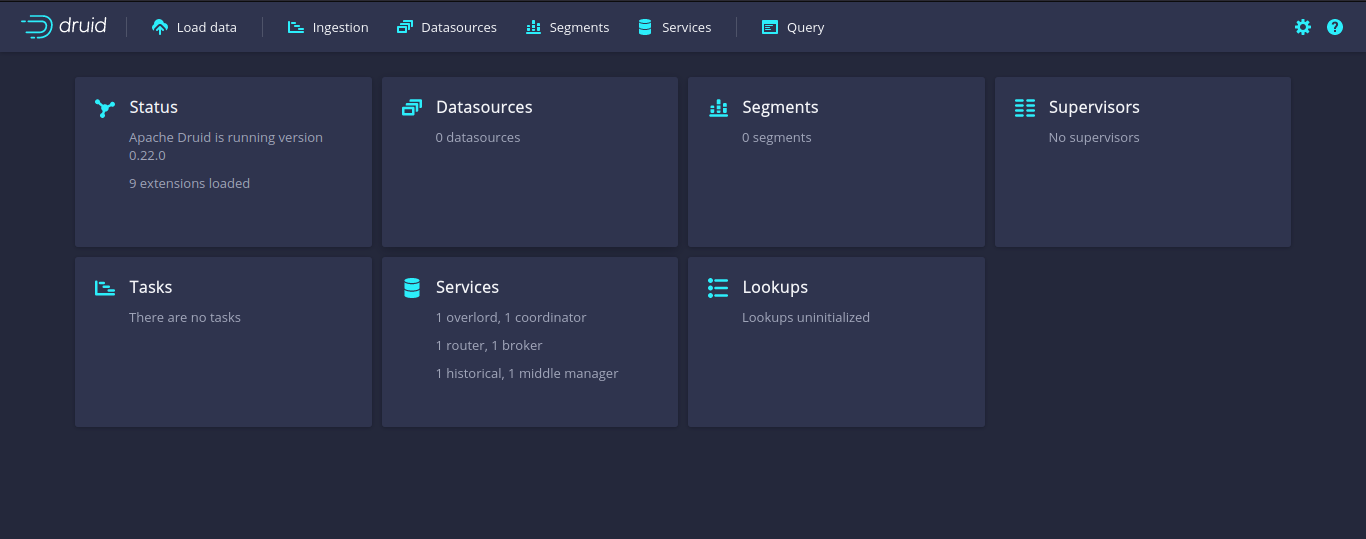
Once Druid is started, go to http://localhost:8888.
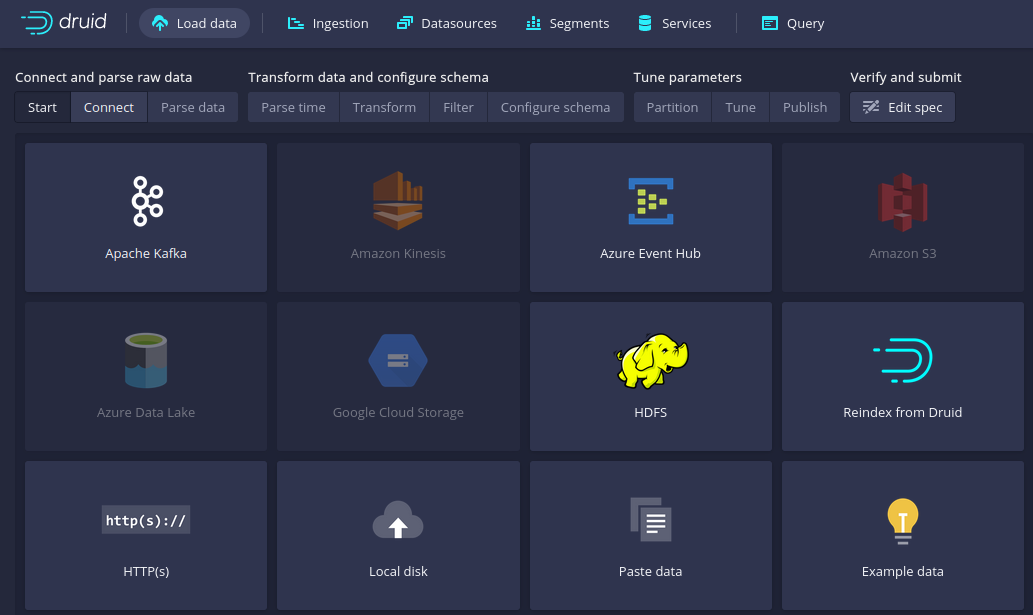
The next thing that you have to do is add Kafka as a datasource to Druid.
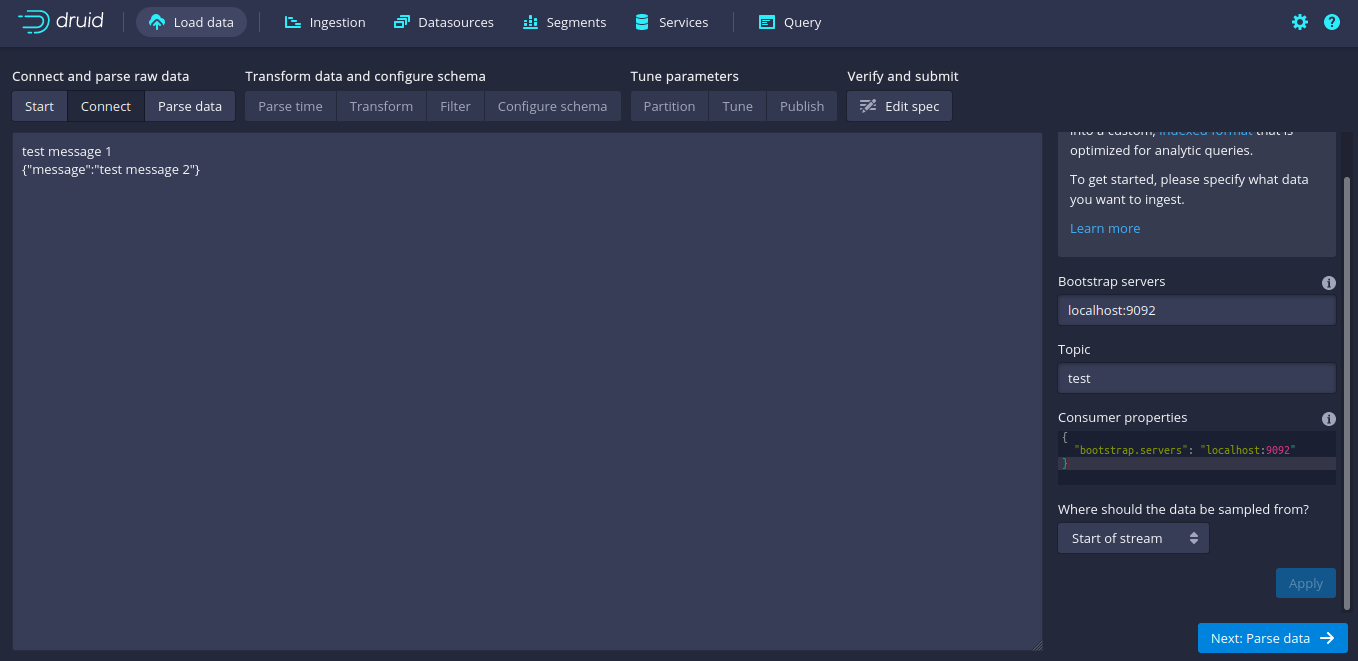
To ingest data, add the broker and topic properties.
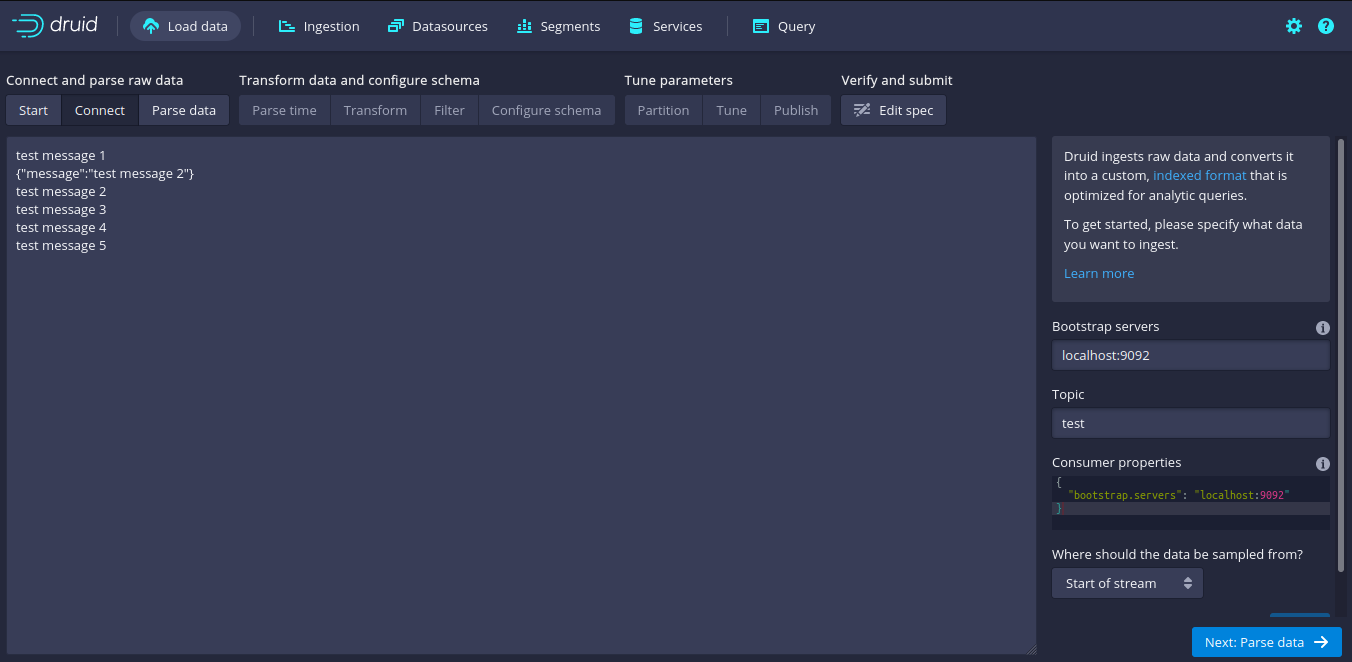
To view sample data, you can add a few data from the kafka-console-producer.
kafka_2.13-3.0.0/bin$ ./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test >test message 1 >test message 2 >test message 3 >test message 4 >test message 5
Once you’re able to ingest the kafka data, you will be able to run analytics on the data.